
Learning to Demap: Database Generation, Preprocessing, Postprocessing, Training, Validation and Inferences from the LLRNet
This notebook introduces the users to few functionalities provided by the 5G Toolkit such as
PDSCH Transmitter Chain
PDSCH Receiver
Symbol Demapper.
The PDSCH transmitter is compliant with 5G standards defined in 38.211, 38.212 and 38.214. Finally, the tutorial will teach the user to replace one of the PDSCH receiver’s module called Symbol Demapper with a neural network based Symbol Demapper (LLRNet).
Conventional Techniques
- Log MAP Demapper
- Optimal for AWGN Noise ==> Highest possible data rate | Lowest possible Block error rate
- Complexity: Combinatorial ==> Consumes a lot of power
- Not suitable for Internet of Things (**IoT**) devices.
- Max log MAP Demapper
- Sub-Optimal performance ==> 3 dB loss in performance
- Complexity: Linear ==> Consumes a less power compared to log-MAP
Proposed Techniques
- LLRNet
- B(L)ER and Throughput Performance matches Log MAP Demapper
- Complexity: Even lower than Max log MAP Demapper
Finally, the user will be able to rapidly evaluate and compare the
Bit Error rate vs SNR
Block Error rate vs SNR
Throughput/Data rate vs SNR
Computational Complexity of Log-MAP, Max-Log-MAP and LLRNet methods.
Table of Contents
Note: The simulation might take upto 2-3 hour to complete for this projects because of 10 SNR points for each link, 3 modulation orders, 100 batches considered for simulation, and 3 methods to evaluate. Furthermore, simulation consumes 25-30 GB of RAM while simulation. To reduce the simulation time and memory consumption please excercise following options:
Reduce batches to a lower number (
numFrames)Reduce the number of SNR points (
numPoints)Reduces the number of training samples (
numTrainingSamples).
Import Libraries
Import Python Libraries
[1]:
# %matplotlib widget
import matplotlib.pyplot as plt
from matplotlib.ticker import FormatStrFormatter
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "-1"
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
Import 5G Toolkit Modules
[2]:
from llrNet import LLRNet
from toolkit5G.SymbolMapping import Demapper
from toolkit5G.SymbolMapping import Mapper
[3]:
# from IPython.display import display, HTML
# display(HTML("<style>.container { width:70% !important; }</style>"))
Learning to Demap the Symbols
The Mapping between input and output is learned for a specific modulation order at a given SNR. The neural network model used for learning looks as follows: 
The following inputs are expected for the experiments
modOrder: Defines the modulation order.nodesPerLayer: Defines the number of nodes used for hidden layers. Number of nodes for input layer is 2 and number of nodes at the output layer ismodOrder. Number of hidden layers = np.size(nodesPerLayer).activationfunctions: Defines the activation function used for each layer. Length should equal to np.size(nodesPerLayer) + 1. The last value defines the activation function for the output layer.numTrainingSamples: Defines the number of samples used for training the model.numTestSamples: Defines the number of samples used for testing the performance of the model.SNR: SNR value.
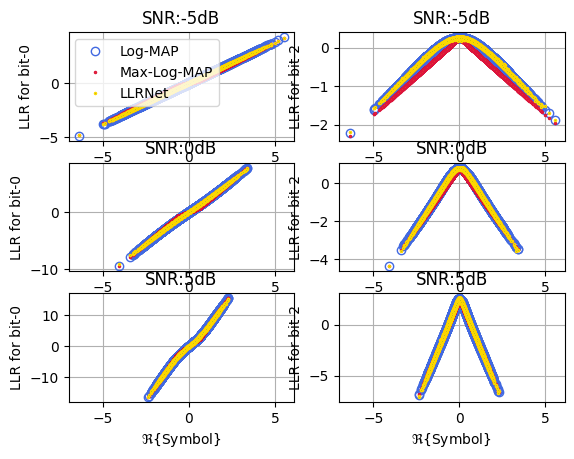
Input Output Mapping for M = 4
[4]:
modOrder = int(np.random.choice([2,4,6,8,10]))
nodesPerLayer = np.array([32, 64, 32])
activationfunctions = np.array(['relu', 'relu', 'relu', 'linear'])
numTrainingSamples = 2**8
llrNet = LLRNet(modOrder = modOrder, nodesPerLayer = nodesPerLayer,
numTrainingSamples = numTrainingSamples, activationfunctions = activationfunctions)
fig, ax = llrNet.displayMapping(modOrder = 4, bitLocations = [0,2], SNRdB = [-5,0,5],
numSamples = 2**16, displayRealPart = True)
************************************ Training the Model ***********************************
...........................................................................................
*********************************** Evaluating the Model **********************************
...........................................................................................
512/512 [==============================] - 0s 651us/step - loss: 1.0184e-04 - accuracy: 0.9938
Training Accuracy: 99.38
512/512 [==============================] - 0s 580us/step
************************************ Training the Model ***********************************
...........................................................................................
*********************************** Evaluating the Model **********************************
...........................................................................................
512/512 [==============================] - 0s 617us/step - loss: 4.5833e-04 - accuracy: 0.9970
Training Accuracy: 99.70
512/512 [==============================] - 0s 620us/step
************************************ Training the Model ***********************************
...........................................................................................
*********************************** Evaluating the Model **********************************
...........................................................................................
512/512 [==============================] - 0s 660us/step - loss: 0.0046 - accuracy: 0.9902
Training Accuracy: 99.02
512/512 [==============================] - 0s 628us/step
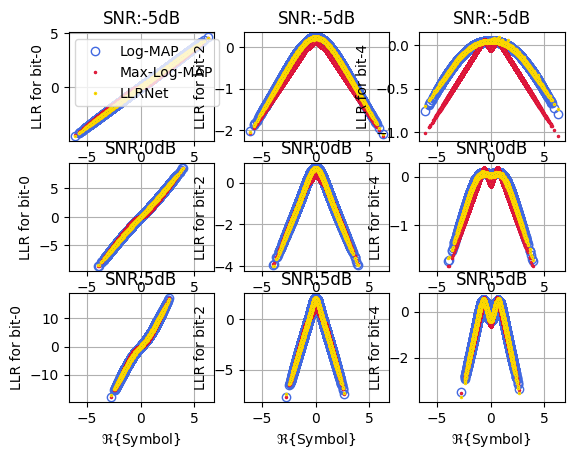
Input Output Mapping for M = 6
[5]:
modOrder = int(np.random.choice([2,4,6,8,10]))
nodesPerLayer = np.array([32, 64, 32])
activationfunctions = np.array(['relu', 'relu', 'relu', 'linear'])
numTrainingSamples = 2**16
SNR = 10
llrNet = LLRNet(modOrder = modOrder, nodesPerLayer = nodesPerLayer,
numTrainingSamples = numTrainingSamples, activationfunctions = activationfunctions)
fig, ax = llrNet.displayMapping(modOrder = 6, bitLocations = [0,2,4], SNRdB = [-5,0,5],
numSamples = 3*2**18, displayRealPart = True)
************************************ Training the Model ***********************************
...........................................................................................
*********************************** Evaluating the Model **********************************
...........................................................................................
4096/4096 [==============================] - 2s 585us/step - loss: 2.5838e-05 - accuracy: 0.9895
Training Accuracy: 98.95
4096/4096 [==============================] - 2s 525us/step
************************************ Training the Model ***********************************
...........................................................................................
*********************************** Evaluating the Model **********************************
...........................................................................................
4096/4096 [==============================] - 2s 579us/step - loss: 2.0524e-04 - accuracy: 0.9724
Training Accuracy: 97.24
4096/4096 [==============================] - 2s 532us/step
************************************ Training the Model ***********************************
...........................................................................................
*********************************** Evaluating the Model **********************************
...........................................................................................
4096/4096 [==============================] - 3s 595us/step - loss: 7.8327e-04 - accuracy: 0.9935
Training Accuracy: 99.35
4096/4096 [==============================] - 2s 559us/step
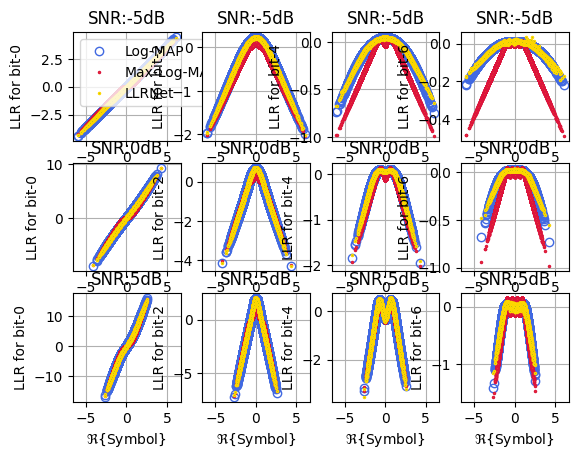
Input Output Mapping for M = 8
[6]:
modOrder = int(np.random.choice([2,4,6,8,10]))
nodesPerLayer = np.array([32, 64, 32])
activationfunctions = np.array(['relu', 'relu', 'relu', 'linear'])
numTrainingSamples = 2**16
SNR = 10
llrNet = LLRNet(modOrder = modOrder, nodesPerLayer = nodesPerLayer,
numTrainingSamples = numTrainingSamples,
activationfunctions = activationfunctions)
fig, ax = llrNet.displayMapping(modOrder = 8, bitLocations = [0,2,4,6], SNRdB = [-5,0,5],
numSamples = 2**20, displayRealPart = True)
************************************ Training the Model ***********************************
...........................................................................................
*********************************** Evaluating the Model **********************************
...........................................................................................
4096/4096 [==============================] - 2s 591us/step - loss: 1.0649e-05 - accuracy: 0.9734
Training Accuracy: 97.34
4096/4096 [==============================] - 2s 528us/step
************************************ Training the Model ***********************************
...........................................................................................
*********************************** Evaluating the Model **********************************
...........................................................................................
4096/4096 [==============================] - 3s 611us/step - loss: 5.3079e-05 - accuracy: 0.9711
Training Accuracy: 97.11
4096/4096 [==============================] - 2s 556us/step
************************************ Training the Model ***********************************
...........................................................................................
*********************************** Evaluating the Model **********************************
...........................................................................................
4096/4096 [==============================] - 3s 617us/step - loss: 4.3204e-04 - accuracy: 0.9839
Training Accuracy: 98.39
4096/4096 [==============================] - 2s 525us/step
Throughput and BER Performance of LLRnet
Import Libraries
[7]:
from toolkit5G.PhysicalChannels.PDSCH import ComputeTransportBlockSize
from toolkit5G.PhysicalChannels import PDSCHLowerPhy
from toolkit5G.PhysicalChannels import PDSCHDecoderLowerPhy
from toolkit5G.PhysicalChannels import PDSCHUpperPhy
from toolkit5G.PhysicalChannels import PDSCHDecoderUpperPhy
from toolkit5G.Configurations import TimeFrequency5GParameters
from toolkit5G.ChannelProcessing import AddNoise
Simulation Parameters
Parameters |
Variable |
Values |
|---|---|---|
Number of frames |
|
200 |
Subcarrier Spacing |
|
30 KHz |
Bandwidth |
|
20 MHz |
Number of Resource Blocks |
|
51 |
Number of Transmit Antennas |
|
8 |
Number of Receive Antennas |
|
2 |
Number of layers |
|
2 |
Physical Channel |
|
Simulation are carried out for Physical Downlink Shared Channel (PDSCH) |
Channel Coder |
|
PDSCH uses Low density parity check codes internally |
Code rate |
|
0.4785 |
Modulation Order |
|
16-QAM, 64-QAM, 256–QAM |
[8]:
# Simulation Parameters
numBSs = 1
numUEs = 1
numFrames = 100
scSpacing = 30000
Bandwidth = 20*10**6
nSymbolFrame = 140*int(scSpacing/15000); # Number of OFDM symbols per frame (Its a function of subcarrier spacing)
slotDuration = 0.001/(scSpacing/15000)
tfParams = TimeFrequency5GParameters(Bandwidth, scSpacing)
tfParams(nSymbolFrame, typeCP = "normal")
numRBs = tfParams.numRBs
# Antenna and Precoding Parameters
numTx = 8
numRx = 2
numLayers = 2
PDSCH Parameters
[9]:
# Set start symbol and number of symbols for DMRS transmission.
startSymbol = 0
numSymbols = 13
dmrsREs = 0
scalingField = '00'
# Modulation and Coding Rate Parameters
codeRate = 0.4785
modOrders = [4, 6, 8] ## For 16-QAM, 64-QAM and 256-QAM
numLayers = 2
numTBs = 1
additionalOverhead = 0
print("************ PDSCH Parameters *************")
print()
print(" startSymbol: "+str(startSymbol))
print(" numSymbols: "+str(numSymbols))
print(" dmrsREs: "+str(dmrsREs))
print(" scalingField: "+str(scalingField))
print(" modOrder: "+str(modOrders))
print(" codeRate: "+str(codeRate))
print(" numLayers: "+str(numLayers))
print(" numTBs: "+str(numTBs))
print(" additionalOverhead: "+str(additionalOverhead))
print()
print("********************************************")
enableLBRM = False # Flag to enable/disbale "Limited buffer rate matching"
rvid1 = 0 # Redundency version-ID for TB-1: As per 3GPP TS38.212
rvid2 = 0 # Redundency version-ID for TB-2: As per 3GPP TS38.212
************ PDSCH Parameters *************
startSymbol: 0
numSymbols: 13
dmrsREs: 0
scalingField: 00
modOrder: [4, 6, 8]
codeRate: 0.4785
numLayers: 2
numTBs: 1
additionalOverhead: 0
********************************************
LLRnet Parameters
Training Framework
The artificial neural network (ANN) is trained to mimic a optimal method with lower complexity.
The input to ANN model and optimal log-MAP method is the estimated equalized symbol and the output of the log-MAP method is fed to ANN output for learning the model parameters using adaptive moment estimation (ADAM) optimizer while Levenberg-Marquardt backpropagation.
We are assuming
epochs= 4,batch_size= 32 for reasonable complexing while training.Note: We are assuming slighly large neural networks compared to what paper claims. As we were unable to reproduce the exact same results.
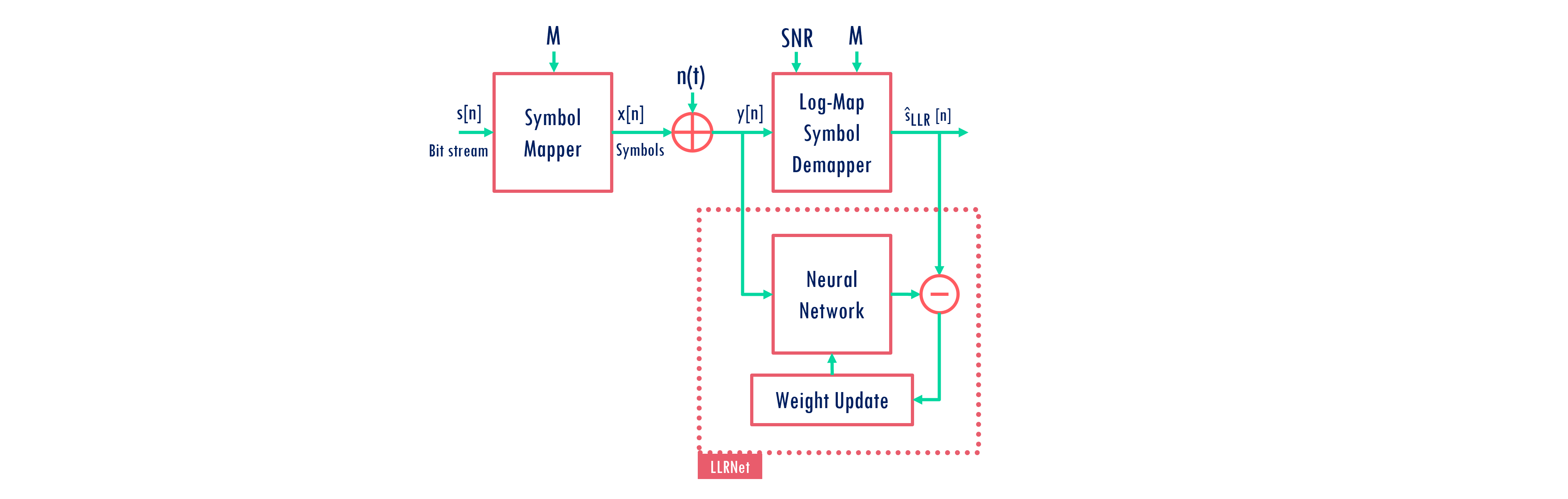
Deployment Framework
The trained model is used to predict the llr for each bits for the received symbols.
The received symbol is represented using the its real and imaginary part and fed to the model.
The ANN model emits
M-llr estimates one for each bit.

[10]:
nodesPerLayer = np.array([32, 64, 32])
activationfunctions = np.array(['relu', 'relu', 'relu', 'linear'])
numTrainingSamples = 3*2**14
Simulation Section
The simulation is carried out for 3 modulation orders 16-QAM (M=4), 64-QAM (M=6), and 256-QAM (M=8).
For M = 4:
The simulation is carried out for SNR (dB) in the range ().
For M = 6:
The simulation is carried out for SNR (dB) in the range ().
For M = 8:
The simulation is carried out for SNR (dB) in the range ().
[11]:
modOrders = np.array([4, 6, 8]) ## For 16-QAM, 64-QAM and 256-QAM
numPoints = 10
SNRdB = np.array([np.linspace(5.4, 6.4, numPoints),
np.linspace(9.5, 10.8, numPoints),
np.linspace(13.4, 14.4, numPoints)])
BER = np.zeros((3, modOrders.size, SNRdB.shape[-1]))
BLER = np.zeros((3, modOrders.size, SNRdB.shape[-1]))
Throughput = np.zeros((3, modOrders.size, SNRdB.shape[-1]))
SNR = 10**(0.1*SNRdB)
maxThroughput = (14*numRBs*12*modOrders*numLayers*codeRate)/slotDuration
mcsIdx = 0
for modorder in modOrders:
## PDSCH-transmitter chain object
pdschUpPhy = PDSCHUpperPhy(numTBs = numTBs, mcsIndex = np.array([modorder, codeRate]),
symbolsPerSlot = numSymbols, numRB = numRBs,
numlayers = [numLayers], scalingField = scalingField,
additionalOverhead = additionalOverhead, dmrsREs = dmrsREs,
pdschTable = None, verbose=False)
codewords = pdschUpPhy(rvid = [rvid1, rvid2], enableLBRM = [False, False],
numBatch = numFrames, numBSs = numBSs)
symbols = Mapper("qam", pdschUpPhy.modOrder)(codewords[0])
snrIndex = 0
for snr in SNR[mcsIdx]:
# log-MAP Decoder
rxSymbols = np.complex64(AddNoise()(symbols, 1/snr))
llrs = Demapper("app", "qam", int(modorder), hard_out = False)([rxSymbols, np.float32(1/snr)])
# Receiver: Upper Physical layer
# pdschDecoderUpperPhy = PDSCHDecoderUpperPhy(numTBs, [modorder, codeRate], numSymbols,
# numRBs, [numLayers], scalingField,
# [rvid1], additionalOverhead, dmrsREs,
# pdschTable = None, verbose=False)
pdschDecoderUpperPhy = PDSCHDecoderUpperPhy(numTBs, np.array([modorder, codeRate]), numSymbols,
numRBs, [numLayers], scalingField,
additionalOverhead, dmrsREs,
enableLBRM=[False, False], pdschTable=None,
rvid=[rvid1], verbose=False)
tbEst = pdschDecoderUpperPhy([llrs])
BER[0, mcsIdx, snrIndex] = np.mean(np.abs(tbEst[0] - pdschUpPhy.tblock1))
if (pdschDecoderUpperPhy.numCBs == 1):
BLER[0, mcsIdx, snrIndex] = 1 - np.mean(pdschDecoderUpperPhy.crcCheckTBs)
else:
BLER[0, mcsIdx, snrIndex] = 1 - np.mean(pdschDecoderUpperPhy.crcCheckforCBs)
Throughput[0, mcsIdx, snrIndex] = (1-BLER[0, mcsIdx, snrIndex])*pdschUpPhy.tblock1.shape[-1]/slotDuration
print()
print("+++++++++++ [ snrIndex: "+str(snrIndex)+" | modorder: "+str(modorder)+"] +++++++++++")
print("===================================================")
print(" **************** log-MAP **************** ")
print("mod-Order: "+str(modorder)+" | SNR (dB): "+str(SNRdB[mcsIdx, snrIndex]))
print(" BER: "+str(BER[0, mcsIdx, snrIndex]))
print(" BLER: "+str(BLER[0, mcsIdx, snrIndex]))
print(" Throughput: "+str(Throughput[0, mcsIdx, snrIndex]))
print(".......................................................")
# max-log-MAP Decoder
llrs = Demapper("maxlog", "qam", int(modorder), hard_out = False)([rxSymbols, np.float32(1/snr)])
pdschDecoderUpperPhy = PDSCHDecoderUpperPhy(numTBs, np.array([modorder, codeRate]), numSymbols,
numRBs, [numLayers], scalingField,
additionalOverhead, dmrsREs,
enableLBRM=[False, False], pdschTable=None,
rvid=[rvid1], verbose=False)
tbEst = pdschDecoderUpperPhy([llrs])
BER[1, mcsIdx, snrIndex] = np.mean(np.abs(tbEst[0] - pdschUpPhy.tblock1))
if (pdschDecoderUpperPhy.numCBs == 1):
BLER[1, mcsIdx, snrIndex] = 1 - np.mean(pdschDecoderUpperPhy.crcCheckTBs)
else:
BLER[1, mcsIdx, snrIndex] = 1 - np.mean(pdschDecoderUpperPhy.crcCheckforCBs)
Throughput[1, mcsIdx, snrIndex] = (1-BLER[1, mcsIdx, snrIndex])*pdschUpPhy.tblock1.shape[-1]/slotDuration
print(" **************** max-log-MAP **************** ")
print("mod-Order: "+str(modorder)+" | SNR (dB): "+str(SNRdB[mcsIdx, snrIndex]))
print(" BER: "+str(BER[1, mcsIdx, snrIndex]))
print(" BLER: "+str(BLER[1, mcsIdx, snrIndex]))
print(" Throughput: "+str(Throughput[1, mcsIdx, snrIndex]))
print(".......................................................")
llrNet = LLRNet(modOrder = int(modorder), nodesPerLayer = nodesPerLayer,
numTrainingSamples = numTrainingSamples, activationfunctions = activationfunctions)
llrs = llrNet(snr, rxSymbols)
# Receiver: Upper Physical layer
pdschDecoderUpperPhy = PDSCHDecoderUpperPhy(numTBs, np.array([modorder, codeRate]), numSymbols,
numRBs, [numLayers], scalingField,
additionalOverhead, dmrsREs,
enableLBRM=[False, False], pdschTable=None,
rvid=[rvid1], verbose=False)
tbEst = pdschDecoderUpperPhy([llrs])
BER[2, mcsIdx, snrIndex] = np.mean(np.abs(tbEst[0] - pdschUpPhy.tblock1))
if (pdschDecoderUpperPhy.numCBs == 1):
BLER[2, mcsIdx, snrIndex] = 1 - np.mean(pdschDecoderUpperPhy.crcCheckTBs)
else:
BLER[2, mcsIdx, snrIndex] = 1 - np.mean(pdschDecoderUpperPhy.crcCheckforCBs)
Throughput[2, mcsIdx, snrIndex] = (1-BLER[2, mcsIdx, snrIndex])*pdschUpPhy.tblock1.shape[-1]/slotDuration
print(" ******************* LLRnet ****************** ")
print("mod-Order: "+str(modorder)+" | SNR (dB): "+str(SNRdB[mcsIdx, snrIndex]))
print(" BER: "+str(BER[2, mcsIdx, snrIndex]))
print(" BLER: "+str(BLER[2, mcsIdx, snrIndex]))
print(" Throughput: "+str(Throughput[2, mcsIdx, snrIndex]))
print("_______________________________________________________")
print()
snrIndex += 1
mcsIdx += 1
+++++++++++ [ snrIndex: 0 | modorder: 4] +++++++++++
===================================================
**************** log-MAP ****************
mod-Order: 4 | SNR (dB): 5.4
BER: 0.025147934868943605
BLER: 1.0
Throughput: 0.0
.......................................................
**************** max-log-MAP ****************
mod-Order: 4 | SNR (dB): 5.4
BER: 0.028224781572676726
BLER: 1.0
Throughput: 0.0
.......................................................
************************************ Training the Model ***********************************
...........................................................................................
Epoch 1/4
1536/1536 [==============================] - 2s 776us/step - loss: 0.7875 - accuracy: 0.9571
Epoch 2/4
1536/1536 [==============================] - 1s 767us/step - loss: 0.0052 - accuracy: 0.9923
Epoch 3/4
1536/1536 [==============================] - 1s 761us/step - loss: 0.0027 - accuracy: 0.9948
Epoch 4/4
1536/1536 [==============================] - 1s 757us/step - loss: 0.0019 - accuracy: 0.9952
*********************************** Evaluating the Model **********************************
...........................................................................................
1536/1536 [==============================] - 1s 647us/step - loss: 0.0018 - accuracy: 0.9948
Training Accuracy: 99.48
49725/49725 [==============================] - 26s 523us/step
******************* LLRnet ******************
mod-Order: 4 | SNR (dB): 5.4
BER: 0.02535378607360339
BLER: 1.0
Throughput: 0.0
_______________________________________________________
+++++++++++ [ snrIndex: 1 | modorder: 4] +++++++++++
===================================================
**************** log-MAP ****************
mod-Order: 4 | SNR (dB): 5.511111111111111
BER: 0.016092136616362194
BLER: 0.995
Throughput: 302160.00000000023
.......................................................
**************** max-log-MAP ****************
mod-Order: 4 | SNR (dB): 5.511111111111111
BER: 0.01816587238549113
BLER: 1.0
Throughput: 0.0
.......................................................
************************************ Training the Model ***********************************
...........................................................................................
Epoch 1/4
1536/1536 [==============================] - 2s 943us/step - loss: 0.8334 - accuracy: 0.9536
Epoch 2/4
1536/1536 [==============================] - 1s 942us/step - loss: 0.0104 - accuracy: 0.9900
Epoch 3/4
1536/1536 [==============================] - 1s 950us/step - loss: 0.0034 - accuracy: 0.9942
Epoch 4/4
1536/1536 [==============================] - 1s 945us/step - loss: 0.0020 - accuracy: 0.9954
*********************************** Evaluating the Model **********************************
...........................................................................................
1536/1536 [==============================] - 1s 675us/step - loss: 0.0013 - accuracy: 0.9964
Training Accuracy: 99.64
49725/49725 [==============================] - 30s 593us/step
******************* LLRnet ******************
mod-Order: 4 | SNR (dB): 5.511111111111111
BER: 0.01622584061424411
BLER: 0.9975
Throughput: 151079.99999999677
_______________________________________________________
+++++++++++ [ snrIndex: 2 | modorder: 4] +++++++++++
===================================================
**************** log-MAP ****************
mod-Order: 4 | SNR (dB): 5.622222222222223
BER: 0.0077429176595181365
BLER: 0.9
Throughput: 6043199.999999999
.......................................................
**************** max-log-MAP ****************
mod-Order: 4 | SNR (dB): 5.622222222222223
BER: 0.009148795340217104
BLER: 0.9425
Throughput: 3474839.9999999995
.......................................................
************************************ Training the Model ***********************************
...........................................................................................
Epoch 1/4
1536/1536 [==============================] - 2s 1ms/step - loss: 0.8134 - accuracy: 0.9645
Epoch 2/4
1536/1536 [==============================] - 2s 988us/step - loss: 0.0096 - accuracy: 0.9915
Epoch 3/4
1536/1536 [==============================] - 2s 976us/step - loss: 0.0028 - accuracy: 0.9941
Epoch 4/4
1536/1536 [==============================] - 1s 967us/step - loss: 0.0020 - accuracy: 0.9953
*********************************** Evaluating the Model **********************************
...........................................................................................
1536/1536 [==============================] - 1s 678us/step - loss: 0.0021 - accuracy: 0.9961
Training Accuracy: 99.61
49725/49725 [==============================] - 30s 599us/step
******************* LLRnet ******************
mod-Order: 4 | SNR (dB): 5.622222222222223
BER: 0.00787595975642044
BLER: 0.9
Throughput: 6043199.999999999
_______________________________________________________
+++++++++++ [ snrIndex: 3 | modorder: 4] +++++++++++
===================================================
**************** log-MAP ****************
mod-Order: 4 | SNR (dB): 5.733333333333333
BER: 0.003140058247286206
BLER: 0.645
Throughput: 21453360.0
.......................................................
**************** max-log-MAP ****************
mod-Order: 4 | SNR (dB): 5.733333333333333
BER: 0.003892308710616892
BLER: 0.7224999999999999
Throughput: 16769880.000000004
.......................................................
************************************ Training the Model ***********************************
...........................................................................................
Epoch 1/4
1536/1536 [==============================] - 2s 1ms/step - loss: 0.9520 - accuracy: 0.9576
Epoch 2/4
1536/1536 [==============================] - 2s 997us/step - loss: 0.0037 - accuracy: 0.9933
Epoch 3/4
1536/1536 [==============================] - 2s 989us/step - loss: 0.0019 - accuracy: 0.9955
Epoch 4/4
1536/1536 [==============================] - 2s 993us/step - loss: 0.0015 - accuracy: 0.9953
*********************************** Evaluating the Model **********************************
...........................................................................................
1536/1536 [==============================] - 1s 665us/step - loss: 0.0014 - accuracy: 0.9963
Training Accuracy: 99.63
49725/49725 [==============================] - 30s 609us/step
******************* LLRnet ******************
mod-Order: 4 | SNR (dB): 5.733333333333333
BER: 0.003194334127614509
BLER: 0.6525000000000001
Throughput: 21000119.999999996
_______________________________________________________
+++++++++++ [ snrIndex: 4 | modorder: 4] +++++++++++
===================================================
**************** log-MAP ****************
mod-Order: 4 | SNR (dB): 5.844444444444445
BER: 0.000560630129732592
BLER: 0.29000000000000004
Throughput: 42906720.0
.......................................................
**************** max-log-MAP ****************
mod-Order: 4 | SNR (dB): 5.844444444444445
BER: 0.0007045935927985173
BLER: 0.3325
Throughput: 40338360.0
.......................................................
************************************ Training the Model ***********************************
...........................................................................................
Epoch 1/4
1536/1536 [==============================] - 2s 958us/step - loss: 0.9824 - accuracy: 0.9567
Epoch 2/4
1536/1536 [==============================] - 1s 965us/step - loss: 0.0100 - accuracy: 0.9902
Epoch 3/4
1536/1536 [==============================] - 1s 953us/step - loss: 0.0030 - accuracy: 0.9931
Epoch 4/4
1536/1536 [==============================] - 1s 950us/step - loss: 0.0019 - accuracy: 0.9947
*********************************** Evaluating the Model **********************************
...........................................................................................
1536/1536 [==============================] - 1s 675us/step - loss: 0.0015 - accuracy: 0.9950
Training Accuracy: 99.50
49725/49725 [==============================] - 30s 598us/step
******************* LLRnet ******************
mod-Order: 4 | SNR (dB): 5.844444444444445
BER: 0.0005801562086311888
BLER: 0.29500000000000004
Throughput: 42604560.0
_______________________________________________________
+++++++++++ [ snrIndex: 5 | modorder: 4] +++++++++++
===================================================
**************** log-MAP ****************
mod-Order: 4 | SNR (dB): 5.955555555555556
BER: 0.00010424940428911835
BLER: 0.08499999999999996
Throughput: 55295280.0
.......................................................
**************** max-log-MAP ****************
mod-Order: 4 | SNR (dB): 5.955555555555556
BER: 0.0001290706910246227
BLER: 0.10499999999999998
Throughput: 54086640.0
.......................................................
************************************ Training the Model ***********************************
...........................................................................................
Epoch 1/4
1536/1536 [==============================] - 2s 971us/step - loss: 1.0082 - accuracy: 0.9494
Epoch 2/4
1536/1536 [==============================] - 1s 953us/step - loss: 0.0094 - accuracy: 0.9895
Epoch 3/4
1536/1536 [==============================] - 1s 948us/step - loss: 0.0034 - accuracy: 0.9938
Epoch 4/4
1536/1536 [==============================] - 1s 949us/step - loss: 0.0023 - accuracy: 0.9950
*********************************** Evaluating the Model **********************************
...........................................................................................
1536/1536 [==============================] - 1s 652us/step - loss: 0.0015 - accuracy: 0.9954
Training Accuracy: 99.54
49725/49725 [==============================] - 30s 595us/step
******************* LLRnet ******************
mod-Order: 4 | SNR (dB): 5.955555555555556
BER: 0.00010325655281969817
BLER: 0.08499999999999996
Throughput: 55295280.0
_______________________________________________________
+++++++++++ [ snrIndex: 6 | modorder: 4] +++++++++++
===================================================
**************** log-MAP ****************
mod-Order: 4 | SNR (dB): 6.066666666666667
BER: 7.942811755361398e-06
BLER: 0.010000000000000009
Throughput: 59827680.0
.......................................................
**************** max-log-MAP ****************
mod-Order: 4 | SNR (dB): 6.066666666666667
BER: 1.1252316653428647e-05
BLER: 0.015000000000000013
Throughput: 59525519.99999999
.......................................................
************************************ Training the Model ***********************************
...........................................................................................
Epoch 1/4
1536/1536 [==============================] - 2s 972us/step - loss: 1.1142 - accuracy: 0.9508
Epoch 2/4
1536/1536 [==============================] - 1s 951us/step - loss: 0.0042 - accuracy: 0.9925
Epoch 3/4
1536/1536 [==============================] - 1s 942us/step - loss: 0.0019 - accuracy: 0.9949
Epoch 4/4
1536/1536 [==============================] - 1s 947us/step - loss: 0.0016 - accuracy: 0.9954
*********************************** Evaluating the Model **********************************
...........................................................................................
1536/1536 [==============================] - 1s 666us/step - loss: 0.0012 - accuracy: 0.9960
Training Accuracy: 99.60
49725/49725 [==============================] - 30s 593us/step
******************* LLRnet ******************
mod-Order: 4 | SNR (dB): 6.066666666666667
BER: 9.597564204395023e-06
BLER: 0.012499999999999956
Throughput: 59676600.00000001
_______________________________________________________
+++++++++++ [ snrIndex: 7 | modorder: 4] +++++++++++
===================================================
**************** log-MAP ****************
mod-Order: 4 | SNR (dB): 6.177777777777778
BER: 3.3095048980672493e-07
BLER: 0.0024999999999999467
Throughput: 60280920.00000001
.......................................................
**************** max-log-MAP ****************
mod-Order: 4 | SNR (dB): 6.177777777777778
BER: 0.0
BLER: 0.0
Throughput: 60432000.0
.......................................................
************************************ Training the Model ***********************************
...........................................................................................
Epoch 1/4
1536/1536 [==============================] - 2s 945us/step - loss: 1.0939 - accuracy: 0.9534
Epoch 2/4
1536/1536 [==============================] - 1s 930us/step - loss: 0.0038 - accuracy: 0.9945
Epoch 3/4
1536/1536 [==============================] - 1s 918us/step - loss: 0.0020 - accuracy: 0.9953
Epoch 4/4
1536/1536 [==============================] - 1s 926us/step - loss: 0.0016 - accuracy: 0.9956
*********************************** Evaluating the Model **********************************
...........................................................................................
1536/1536 [==============================] - 1s 679us/step - loss: 0.0017 - accuracy: 0.9953
Training Accuracy: 99.53
49725/49725 [==============================] - 28s 569us/step
******************* LLRnet ******************
mod-Order: 4 | SNR (dB): 6.177777777777778
BER: 3.3095048980672493e-07
BLER: 0.0024999999999999467
Throughput: 60280920.00000001
_______________________________________________________
+++++++++++ [ snrIndex: 8 | modorder: 4] +++++++++++
===================================================
**************** log-MAP ****************
mod-Order: 4 | SNR (dB): 6.28888888888889
BER: 6.619009796134499e-07
BLER: 0.0050000000000000044
Throughput: 60129839.99999999
.......................................................
**************** max-log-MAP ****************
mod-Order: 4 | SNR (dB): 6.28888888888889
BER: 6.619009796134499e-07
BLER: 0.0024999999999999467
Throughput: 60280920.00000001
.......................................................
************************************ Training the Model ***********************************
...........................................................................................
Epoch 1/4
1536/1536 [==============================] - 2s 935us/step - loss: 1.0920 - accuracy: 0.9517
Epoch 2/4
1536/1536 [==============================] - 1s 917us/step - loss: 0.0095 - accuracy: 0.9910
Epoch 3/4
1536/1536 [==============================] - 1s 924us/step - loss: 0.0037 - accuracy: 0.9939
Epoch 4/4
1536/1536 [==============================] - 1s 909us/step - loss: 0.0026 - accuracy: 0.9953
*********************************** Evaluating the Model **********************************
...........................................................................................
1536/1536 [==============================] - 1s 655us/step - loss: 0.0024 - accuracy: 0.9964
Training Accuracy: 99.64
49725/49725 [==============================] - 28s 569us/step
******************* LLRnet ******************
mod-Order: 4 | SNR (dB): 6.28888888888889
BER: 3.3095048980672493e-07
BLER: 0.0024999999999999467
Throughput: 60280920.00000001
_______________________________________________________
+++++++++++ [ snrIndex: 9 | modorder: 4] +++++++++++
===================================================
**************** log-MAP ****************
mod-Order: 4 | SNR (dB): 6.4
BER: 0.0
BLER: 0.0
Throughput: 60432000.0
.......................................................
**************** max-log-MAP ****************
mod-Order: 4 | SNR (dB): 6.4
BER: 0.0
BLER: 0.0
Throughput: 60432000.0
.......................................................
************************************ Training the Model ***********************************
...........................................................................................
Epoch 1/4
1536/1536 [==============================] - 2s 916us/step - loss: 1.2061 - accuracy: 0.9545
Epoch 2/4
1536/1536 [==============================] - 1s 900us/step - loss: 0.0070 - accuracy: 0.9918
Epoch 3/4
1536/1536 [==============================] - 1s 904us/step - loss: 0.0028 - accuracy: 0.9948
Epoch 4/4
1536/1536 [==============================] - 1s 935us/step - loss: 0.0021 - accuracy: 0.9959
*********************************** Evaluating the Model **********************************
...........................................................................................
1536/1536 [==============================] - 1s 661us/step - loss: 0.0031 - accuracy: 0.9933
Training Accuracy: 99.33
49725/49725 [==============================] - 29s 586us/step
******************* LLRnet ******************
mod-Order: 4 | SNR (dB): 6.4
BER: 0.0
BLER: 0.0
Throughput: 60432000.0
_______________________________________________________
+++++++++++ [ snrIndex: 0 | modorder: 6] +++++++++++
===================================================
**************** log-MAP ****************
mod-Order: 6 | SNR (dB): 9.5
BER: 0.040188703800104114
BLER: 1.0
Throughput: 0.0
.......................................................
**************** max-log-MAP ****************
mod-Order: 6 | SNR (dB): 9.5
BER: 0.04859621724796113
BLER: 1.0
Throughput: 0.0
.......................................................
************************************ Training the Model ***********************************
...........................................................................................
Epoch 1/4
1536/1536 [==============================] - 2s 968us/step - loss: 2.8221 - accuracy: 0.8768
Epoch 2/4
1536/1536 [==============================] - 1s 952us/step - loss: 0.0433 - accuracy: 0.9830
Epoch 3/4
1536/1536 [==============================] - 1s 952us/step - loss: 0.0163 - accuracy: 0.9899
Epoch 4/4
1536/1536 [==============================] - 1s 939us/step - loss: 0.0109 - accuracy: 0.9908
*********************************** Evaluating the Model **********************************
...........................................................................................
1536/1536 [==============================] - 1s 665us/step - loss: 0.0100 - accuracy: 0.9919
Training Accuracy: 99.19
49725/49725 [==============================] - 29s 581us/step
******************* LLRnet ******************
mod-Order: 6 | SNR (dB): 9.5
BER: 0.04115499739718896
BLER: 1.0
Throughput: 0.0
_______________________________________________________
+++++++++++ [ snrIndex: 1 | modorder: 6] +++++++++++
===================================================
**************** log-MAP ****************
mod-Order: 6 | SNR (dB): 9.644444444444444
BER: 0.026602680895366996
BLER: 1.0
Throughput: 0.0
.......................................................
**************** max-log-MAP ****************
mod-Order: 6 | SNR (dB): 9.644444444444444
BER: 0.036362571577303486
BLER: 1.0
Throughput: 0.0
.......................................................
************************************ Training the Model ***********************************
...........................................................................................
Epoch 1/4
1536/1536 [==============================] - 2s 980us/step - loss: 2.9707 - accuracy: 0.8692
Epoch 2/4
1536/1536 [==============================] - 1s 962us/step - loss: 0.1349 - accuracy: 0.9510
Epoch 3/4
1536/1536 [==============================] - 1s 943us/step - loss: 0.0256 - accuracy: 0.9822
Epoch 4/4
1536/1536 [==============================] - 1s 940us/step - loss: 0.0161 - accuracy: 0.9851
*********************************** Evaluating the Model **********************************
...........................................................................................
1536/1536 [==============================] - 1s 655us/step - loss: 0.0138 - accuracy: 0.9869
Training Accuracy: 98.69
49725/49725 [==============================] - 29s 590us/step
******************* LLRnet ******************
mod-Order: 6 | SNR (dB): 9.644444444444444
BER: 0.028235944820406037
BLER: 1.0
Throughput: 0.0
_______________________________________________________
+++++++++++ [ snrIndex: 2 | modorder: 6] +++++++++++
===================================================
**************** log-MAP ****************
mod-Order: 6 | SNR (dB): 9.78888888888889
BER: 0.014358623980565678
BLER: 0.9833333333333333
Throughput: 1536800.0000000047
.......................................................
**************** max-log-MAP ****************
mod-Order: 6 | SNR (dB): 9.78888888888889
BER: 0.023304919312857886
BLER: 1.0
Throughput: 0.0
.......................................................
************************************ Training the Model ***********************************
...........................................................................................
Epoch 1/4
1536/1536 [==============================] - 2s 946us/step - loss: 3.2150 - accuracy: 0.8748
Epoch 2/4
1536/1536 [==============================] - 1s 942us/step - loss: 0.0673 - accuracy: 0.9768
Epoch 3/4
1536/1536 [==============================] - 1s 926us/step - loss: 0.0209 - accuracy: 0.9893
Epoch 4/4
1536/1536 [==============================] - 1s 918us/step - loss: 0.0149 - accuracy: 0.9908
*********************************** Evaluating the Model **********************************
...........................................................................................
1536/1536 [==============================] - 1s 665us/step - loss: 0.0115 - accuracy: 0.9923
Training Accuracy: 99.23
49725/49725 [==============================] - 30s 594us/step
******************* LLRnet ******************
mod-Order: 6 | SNR (dB): 9.78888888888889
BER: 0.01549540170050321
BLER: 0.985
Throughput: 1383120.0000000012
_______________________________________________________
+++++++++++ [ snrIndex: 3 | modorder: 6] +++++++++++
===================================================
**************** log-MAP ****************
mod-Order: 6 | SNR (dB): 9.933333333333334
BER: 0.005127754641679681
BLER: 0.8066666666666666
Throughput: 17826880.0
.......................................................
**************** max-log-MAP ****************
mod-Order: 6 | SNR (dB): 9.933333333333334
BER: 0.010303444386604198
BLER: 0.97
Throughput: 2766240.0000000023
.......................................................
************************************ Training the Model ***********************************
...........................................................................................
Epoch 1/4
1536/1536 [==============================] - 2s 981us/step - loss: 3.3736 - accuracy: 0.8757
Epoch 2/4
1536/1536 [==============================] - 1s 966us/step - loss: 0.1384 - accuracy: 0.9678
Epoch 3/4
1536/1536 [==============================] - 2s 986us/step - loss: 0.0278 - accuracy: 0.9870
Epoch 4/4
1536/1536 [==============================] - 1s 955us/step - loss: 0.0187 - accuracy: 0.9882
*********************************** Evaluating the Model **********************************
...........................................................................................
1536/1536 [==============================] - 1s 682us/step - loss: 0.0160 - accuracy: 0.9887
Training Accuracy: 98.87
49725/49725 [==============================] - 30s 603us/step
******************* LLRnet ******************
mod-Order: 6 | SNR (dB): 9.933333333333334
BER: 0.006156949505465903
BLER: 0.845
Throughput: 14292240.000000002
_______________________________________________________
+++++++++++ [ snrIndex: 4 | modorder: 6] +++++++++++
===================================================
**************** log-MAP ****************
mod-Order: 6 | SNR (dB): 10.077777777777778
BER: 0.0009125021690091967
BLER: 0.405
Throughput: 54863759.99999999
.......................................................
**************** max-log-MAP ****************
mod-Order: 6 | SNR (dB): 10.077777777777778
BER: 0.0024898056567759846
BLER: 0.685
Throughput: 29045519.999999996
.......................................................
************************************ Training the Model ***********************************
...........................................................................................
Epoch 1/4
1536/1536 [==============================] - 2s 889us/step - loss: 3.4978 - accuracy: 0.8656
Epoch 2/4
1536/1536 [==============================] - 1s 848us/step - loss: 0.1237 - accuracy: 0.9658
Epoch 3/4
1536/1536 [==============================] - 1s 858us/step - loss: 0.0273 - accuracy: 0.9871
Epoch 4/4
1536/1536 [==============================] - 1s 862us/step - loss: 0.0174 - accuracy: 0.9889
*********************************** Evaluating the Model **********************************
...........................................................................................
1536/1536 [==============================] - 1s 644us/step - loss: 0.0151 - accuracy: 0.9886
Training Accuracy: 98.86
49725/49725 [==============================] - 28s 564us/step
******************* LLRnet ******************
mod-Order: 6 | SNR (dB): 10.077777777777778
BER: 0.0012116085372201979
BLER: 0.44333333333333336
Throughput: 51329119.99999999
_______________________________________________________
+++++++++++ [ snrIndex: 5 | modorder: 6] +++++++++++
===================================================
**************** log-MAP ****************
mod-Order: 6 | SNR (dB): 10.222222222222223
BER: 0.00011886170397362485
BLER: 0.11333333333333329
Throughput: 81757760.00000001
.......................................................
**************** max-log-MAP ****************
mod-Order: 6 | SNR (dB): 10.222222222222223
BER: 0.00032838799236508765
BLER: 0.22999999999999998
Throughput: 71000160.0
.......................................................
************************************ Training the Model ***********************************
...........................................................................................
Epoch 1/4
1536/1536 [==============================] - 2s 911us/step - loss: 3.9472 - accuracy: 0.8702
Epoch 2/4
1536/1536 [==============================] - 1s 918us/step - loss: 0.1385 - accuracy: 0.9595
Epoch 3/4
1536/1536 [==============================] - 1s 889us/step - loss: 0.0353 - accuracy: 0.9880
Epoch 4/4
1536/1536 [==============================] - 1s 909us/step - loss: 0.0234 - accuracy: 0.9905
*********************************** Evaluating the Model **********************************
...........................................................................................
1536/1536 [==============================] - 1s 635us/step - loss: 0.0182 - accuracy: 0.9921
Training Accuracy: 99.21
49725/49725 [==============================] - 28s 556us/step
******************* LLRnet ******************
mod-Order: 6 | SNR (dB): 10.222222222222223
BER: 0.00018154606975533577
BLER: 0.135
Throughput: 79759920.0
_______________________________________________________
+++++++++++ [ snrIndex: 6 | modorder: 6] +++++++++++
===================================================
**************** log-MAP ****************
mod-Order: 6 | SNR (dB): 10.366666666666667
BER: 9.326739545375672e-06
BLER: 0.015000000000000013
Throughput: 90824880.0
.......................................................
**************** max-log-MAP ****************
mod-Order: 6 | SNR (dB): 10.366666666666667
BER: 2.017178552837064e-05
BLER: 0.026666666666666616
Throughput: 89749120.00000001
.......................................................
************************************ Training the Model ***********************************
...........................................................................................
Epoch 1/4
1536/1536 [==============================] - 2s 890us/step - loss: 4.3447 - accuracy: 0.8683
Epoch 2/4
1536/1536 [==============================] - 1s 880us/step - loss: 0.0913 - accuracy: 0.9728
Epoch 3/4
1536/1536 [==============================] - 1s 870us/step - loss: 0.0263 - accuracy: 0.9887
Epoch 4/4
1536/1536 [==============================] - 1s 889us/step - loss: 0.0154 - accuracy: 0.9913
*********************************** Evaluating the Model **********************************
...........................................................................................
1536/1536 [==============================] - 1s 634us/step - loss: 0.0113 - accuracy: 0.9928
Training Accuracy: 99.28
49725/49725 [==============================] - 27s 541us/step
******************* LLRnet ******************
mod-Order: 6 | SNR (dB): 10.366666666666667
BER: 1.1929550581294465e-05
BLER: 0.01666666666666672
Throughput: 90671200.0
_______________________________________________________
+++++++++++ [ snrIndex: 7 | modorder: 6] +++++++++++
===================================================
**************** log-MAP ****************
mod-Order: 6 | SNR (dB): 10.511111111111111
BER: 0.0
BLER: 0.0
Throughput: 92208000.0
.......................................................
**************** max-log-MAP ****************
mod-Order: 6 | SNR (dB): 10.511111111111111
BER: 0.0
BLER: 0.0
Throughput: 92208000.0
.......................................................
************************************ Training the Model ***********************************
...........................................................................................
Epoch 1/4
1536/1536 [==============================] - 2s 889us/step - loss: 4.1858 - accuracy: 0.8540
Epoch 2/4
1536/1536 [==============================] - 1s 889us/step - loss: 0.1405 - accuracy: 0.9655
Epoch 3/4
1536/1536 [==============================] - 1s 900us/step - loss: 0.0335 - accuracy: 0.9883
Epoch 4/4
1536/1536 [==============================] - 1s 889us/step - loss: 0.0232 - accuracy: 0.9897
*********************************** Evaluating the Model **********************************
...........................................................................................
1536/1536 [==============================] - 1s 654us/step - loss: 0.0198 - accuracy: 0.9888
Training Accuracy: 98.88
49725/49725 [==============================] - 27s 541us/step
******************* LLRnet ******************
mod-Order: 6 | SNR (dB): 10.511111111111111
BER: 2.1690091965989935e-07
BLER: 0.0016666666666667052
Throughput: 92054319.99999999
_______________________________________________________
+++++++++++ [ snrIndex: 8 | modorder: 6] +++++++++++
===================================================
**************** log-MAP ****************
mod-Order: 6 | SNR (dB): 10.655555555555557
BER: 0.0
BLER: 0.0
Throughput: 92208000.0
.......................................................
**************** max-log-MAP ****************
mod-Order: 6 | SNR (dB): 10.655555555555557
BER: 0.0
BLER: 0.0
Throughput: 92208000.0
.......................................................
************************************ Training the Model ***********************************
...........................................................................................
Epoch 1/4
1536/1536 [==============================] - 2s 902us/step - loss: 4.6813 - accuracy: 0.8733
Epoch 2/4
1536/1536 [==============================] - 1s 905us/step - loss: 0.1776 - accuracy: 0.9657
Epoch 3/4
1536/1536 [==============================] - 1s 905us/step - loss: 0.0431 - accuracy: 0.9854
Epoch 4/4
1536/1536 [==============================] - 1s 923us/step - loss: 0.0256 - accuracy: 0.9884
*********************************** Evaluating the Model **********************************
...........................................................................................
1536/1536 [==============================] - 1s 639us/step - loss: 0.0189 - accuracy: 0.9894
Training Accuracy: 98.94
49725/49725 [==============================] - 28s 557us/step
******************* LLRnet ******************
mod-Order: 6 | SNR (dB): 10.655555555555557
BER: 0.0
BLER: 0.0
Throughput: 92208000.0
_______________________________________________________
+++++++++++ [ snrIndex: 9 | modorder: 6] +++++++++++
===================================================
**************** log-MAP ****************
mod-Order: 6 | SNR (dB): 10.8
BER: 0.0
BLER: 0.0
Throughput: 92208000.0
.......................................................
**************** max-log-MAP ****************
mod-Order: 6 | SNR (dB): 10.8
BER: 0.0
BLER: 0.0
Throughput: 92208000.0
.......................................................
************************************ Training the Model ***********************************
...........................................................................................
Epoch 1/4
1536/1536 [==============================] - 2s 880us/step - loss: 5.2463 - accuracy: 0.8624
Epoch 2/4
1536/1536 [==============================] - 1s 861us/step - loss: 0.1384 - accuracy: 0.9677
Epoch 3/4
1536/1536 [==============================] - 1s 859us/step - loss: 0.0383 - accuracy: 0.9870
Epoch 4/4
1536/1536 [==============================] - 1s 884us/step - loss: 0.0240 - accuracy: 0.9893
*********************************** Evaluating the Model **********************************
...........................................................................................
1536/1536 [==============================] - 1s 655us/step - loss: 0.0174 - accuracy: 0.9910
Training Accuracy: 99.10
49725/49725 [==============================] - 28s 570us/step
******************* LLRnet ******************
mod-Order: 6 | SNR (dB): 10.8
BER: 0.0
BLER: 0.0
Throughput: 92208000.0
_______________________________________________________
+++++++++++ [ snrIndex: 0 | modorder: 8] +++++++++++
===================================================
**************** log-MAP ****************
mod-Order: 8 | SNR (dB): 13.4
BER: 0.009899100172025936
BLER: 0.92
Throughput: 9672959.999999994
.......................................................
**************** max-log-MAP ****************
mod-Order: 8 | SNR (dB): 13.4
BER: 0.026978959904724098
BLER: 1.0
Throughput: 0.0
.......................................................
************************************ Training the Model ***********************************
...........................................................................................
Epoch 1/4
1536/1536 [==============================] - 2s 933us/step - loss: 10.5861 - accuracy: 0.8235
Epoch 2/4
1536/1536 [==============================] - 1s 920us/step - loss: 0.7076 - accuracy: 0.9146
Epoch 3/4
1536/1536 [==============================] - 1s 889us/step - loss: 0.2689 - accuracy: 0.9565
Epoch 4/4
1536/1536 [==============================] - 1s 889us/step - loss: 0.2034 - accuracy: 0.9612
*********************************** Evaluating the Model **********************************
...........................................................................................
1536/1536 [==============================] - 1s 634us/step - loss: 0.1782 - accuracy: 0.9594
Training Accuracy: 95.94
49725/49725 [==============================] - 28s 564us/step
******************* LLRnet ******************
mod-Order: 8 | SNR (dB): 13.4
BER: 0.04042411009659918
BLER: 1.0
Throughput: 0.0
_______________________________________________________
+++++++++++ [ snrIndex: 1 | modorder: 8] +++++++++++
===================================================
**************** log-MAP ****************
mod-Order: 8 | SNR (dB): 13.511111111111111
BER: 0.004650489612280005
BLER: 0.7362500000000001
Throughput: 31890539.99999999
.......................................................
**************** max-log-MAP ****************
mod-Order: 8 | SNR (dB): 13.511111111111111
BER: 0.01804337038507344
BLER: 0.9975
Throughput: 302279.99999999354
.......................................................
************************************ Training the Model ***********************************
...........................................................................................
Epoch 1/4
1536/1536 [==============================] - 2s 972us/step - loss: 10.7435 - accuracy: 0.8228
Epoch 2/4
1536/1536 [==============================] - 1s 930us/step - loss: 0.6509 - accuracy: 0.9322
Epoch 3/4
1536/1536 [==============================] - 1s 961us/step - loss: 0.2652 - accuracy: 0.9601
Epoch 4/4
1536/1536 [==============================] - 1s 940us/step - loss: 0.1813 - accuracy: 0.9653
*********************************** Evaluating the Model **********************************
...........................................................................................
1536/1536 [==============================] - 1s 644us/step - loss: 0.1469 - accuracy: 0.9664
Training Accuracy: 96.64
49725/49725 [==============================] - 28s 556us/step
******************* LLRnet ******************
mod-Order: 8 | SNR (dB): 13.511111111111111
BER: 0.027669544792907237
BLER: 1.0
Throughput: 0.0
_______________________________________________________
+++++++++++ [ snrIndex: 2 | modorder: 8] +++++++++++
===================================================
**************** log-MAP ****************
mod-Order: 8 | SNR (dB): 13.622222222222222
BER: 0.00196969696969697
BLER: 0.49250000000000005
Throughput: 61362839.99999999
.......................................................
**************** max-log-MAP ****************
mod-Order: 8 | SNR (dB): 13.622222222222222
BER: 0.010304684398570862
BLER: 0.96625
Throughput: 4080779.9999999935
.......................................................
************************************ Training the Model ***********************************
...........................................................................................
Epoch 1/4
1536/1536 [==============================] - 2s 910us/step - loss: 12.7789 - accuracy: 0.8164
Epoch 2/4
1536/1536 [==============================] - 1s 889us/step - loss: 1.0580 - accuracy: 0.9194
Epoch 3/4
1536/1536 [==============================] - 1s 879us/step - loss: 0.3600 - accuracy: 0.9580
Epoch 4/4
1536/1536 [==============================] - 1s 869us/step - loss: 0.2619 - accuracy: 0.9620
*********************************** Evaluating the Model **********************************
...........................................................................................
1536/1536 [==============================] - 1s 634us/step - loss: 0.2258 - accuracy: 0.9636
Training Accuracy: 96.36
49725/49725 [==============================] - 28s 559us/step
******************* LLRnet ******************
mod-Order: 8 | SNR (dB): 13.622222222222222
BER: 0.02898752811962419
BLER: 1.0
Throughput: 0.0
_______________________________________________________
+++++++++++ [ snrIndex: 3 | modorder: 8] +++++++++++
===================================================
**************** log-MAP ****************
mod-Order: 8 | SNR (dB): 13.733333333333334
BER: 0.00041898240042344845
BLER: 0.21375
Throughput: 95067060.0
.......................................................
**************** max-log-MAP ****************
mod-Order: 8 | SNR (dB): 13.733333333333334
BER: 0.003805577610162763
BLER: 0.75
Throughput: 30228000.0
.......................................................
************************************ Training the Model ***********************************
...........................................................................................
Epoch 1/4
1536/1536 [==============================] - 2s 907us/step - loss: 12.4401 - accuracy: 0.8270
Epoch 2/4
1536/1536 [==============================] - 1s 875us/step - loss: 0.8994 - accuracy: 0.9237
Epoch 3/4
1536/1536 [==============================] - 1s 859us/step - loss: 0.3270 - accuracy: 0.9573
Epoch 4/4
1536/1536 [==============================] - 1s 900us/step - loss: 0.2392 - accuracy: 0.9637
*********************************** Evaluating the Model **********************************
...........................................................................................
1536/1536 [==============================] - 1s 624us/step - loss: 0.2117 - accuracy: 0.9664
Training Accuracy: 96.64
49725/49725 [==============================] - 28s 560us/step
******************* LLRnet ******************
mod-Order: 8 | SNR (dB): 13.733333333333334
BER: 0.021652937673680032
BLER: 1.0
Throughput: 0.0
_______________________________________________________
+++++++++++ [ snrIndex: 4 | modorder: 8] +++++++++++
===================================================
**************** log-MAP ****************
mod-Order: 8 | SNR (dB): 13.844444444444445
BER: 9.262935027127167e-05
BLER: 0.07125000000000004
Throughput: 112297019.99999999
.......................................................
**************** max-log-MAP ****************
mod-Order: 8 | SNR (dB): 13.844444444444445
BER: 0.000882956199550086
BLER: 0.37124999999999997
Throughput: 76023420.0
.......................................................
************************************ Training the Model ***********************************
...........................................................................................
Epoch 1/4
1536/1536 [==============================] - 2s 920us/step - loss: 13.2444 - accuracy: 0.8299
Epoch 2/4
1536/1536 [==============================] - 1s 869us/step - loss: 0.5827 - accuracy: 0.9457
Epoch 3/4
1536/1536 [==============================] - 1s 889us/step - loss: 0.2849 - accuracy: 0.9601
Epoch 4/4
1536/1536 [==============================] - 1s 884us/step - loss: 0.2227 - accuracy: 0.9648
*********************************** Evaluating the Model **********************************
...........................................................................................
1536/1536 [==============================] - 1s 634us/step - loss: 0.1923 - accuracy: 0.9681
Training Accuracy: 96.81
49725/49725 [==============================] - 28s 568us/step
******************* LLRnet ******************
mod-Order: 8 | SNR (dB): 13.844444444444445
BER: 0.008769849146486701
BLER: 0.88125
Throughput: 14358300.000000002
_______________________________________________________
+++++++++++ [ snrIndex: 5 | modorder: 8] +++++++++++
===================================================
**************** log-MAP ****************
mod-Order: 8 | SNR (dB): 13.955555555555556
BER: 1.60447267434167e-05
BLER: 0.018750000000000044
Throughput: 118644899.99999999
.......................................................
**************** max-log-MAP ****************
mod-Order: 8 | SNR (dB): 13.955555555555556
BER: 0.00021106259097525474
BLER: 0.11250000000000004
Throughput: 107309399.99999999
.......................................................
************************************ Training the Model ***********************************
...........................................................................................
Epoch 1/4
1536/1536 [==============================] - 2s 920us/step - loss: 12.5266 - accuracy: 0.8456
Epoch 2/4
1536/1536 [==============================] - 1s 880us/step - loss: 1.0916 - accuracy: 0.9118
Epoch 3/4
1536/1536 [==============================] - 1s 880us/step - loss: 0.4076 - accuracy: 0.9557
Epoch 4/4
1536/1536 [==============================] - 1s 898us/step - loss: 0.2505 - accuracy: 0.9698
*********************************** Evaluating the Model **********************************
...........................................................................................
1536/1536 [==============================] - 1s 644us/step - loss: 0.2088 - accuracy: 0.9711
Training Accuracy: 97.11
49725/49725 [==============================] - 27s 540us/step
******************* LLRnet ******************
mod-Order: 8 | SNR (dB): 13.955555555555556
BER: 0.005416832076220722
BLER: 0.76125
Throughput: 28867740.0
_______________________________________________________
+++++++++++ [ snrIndex: 6 | modorder: 8] +++++++++++
===================================================
**************** log-MAP ****************
mod-Order: 8 | SNR (dB): 14.066666666666666
BER: 8.270477702792113e-07
BLER: 0.0012499999999999734
Throughput: 120760860.0
.......................................................
**************** max-log-MAP ****************
mod-Order: 8 | SNR (dB): 14.066666666666666
BER: 1.4721450310969962e-05
BLER: 0.018750000000000044
Throughput: 118644899.99999999
.......................................................
************************************ Training the Model ***********************************
...........................................................................................
Epoch 1/4
1536/1536 [==============================] - 2s 920us/step - loss: 14.7788 - accuracy: 0.8309
Epoch 2/4
1536/1536 [==============================] - 1s 859us/step - loss: 0.9726 - accuracy: 0.9291
Epoch 3/4
1536/1536 [==============================] - 1s 869us/step - loss: 0.3830 - accuracy: 0.9591
Epoch 4/4
1536/1536 [==============================] - 1s 897us/step - loss: 0.2585 - accuracy: 0.9626
*********************************** Evaluating the Model **********************************
...........................................................................................
1536/1536 [==============================] - 1s 624us/step - loss: 0.2023 - accuracy: 0.9646
Training Accuracy: 96.46
49725/49725 [==============================] - 28s 565us/step
******************* LLRnet ******************
mod-Order: 8 | SNR (dB): 14.066666666666666
BER: 0.0014949715495567023
BLER: 0.405
Throughput: 71942640.0
_______________________________________________________
+++++++++++ [ snrIndex: 7 | modorder: 8] +++++++++++
===================================================
**************** log-MAP ****************
mod-Order: 8 | SNR (dB): 14.177777777777777
BER: 0.0
BLER: 0.0
Throughput: 120912000.0
.......................................................
**************** max-log-MAP ****************
mod-Order: 8 | SNR (dB): 14.177777777777777
BER: 3.308191081116845e-07
BLER: 0.0012499999999999734
Throughput: 120760860.0
.......................................................
************************************ Training the Model ***********************************
...........................................................................................
Epoch 1/4
1536/1536 [==============================] - 2s 899us/step - loss: 16.7222 - accuracy: 0.8061
Epoch 2/4
1536/1536 [==============================] - 1s 879us/step - loss: 1.6367 - accuracy: 0.8986
Epoch 3/4
1536/1536 [==============================] - 1s 889us/step - loss: 0.5433 - accuracy: 0.9480
Epoch 4/4
1536/1536 [==============================] - 1s 879us/step - loss: 0.3280 - accuracy: 0.9633
*********************************** Evaluating the Model **********************************
...........................................................................................
1536/1536 [==============================] - 1s 613us/step - loss: 0.2776 - accuracy: 0.9649
Training Accuracy: 96.49
49725/49725 [==============================] - 29s 587us/step
******************* LLRnet ******************
mod-Order: 8 | SNR (dB): 14.177777777777777
BER: 0.0021064906709011514
BLER: 0.53
Throughput: 56828640.0
_______________________________________________________
+++++++++++ [ snrIndex: 8 | modorder: 8] +++++++++++
===================================================
**************** log-MAP ****************
mod-Order: 8 | SNR (dB): 14.28888888888889
BER: 0.0
BLER: 0.0
Throughput: 120912000.0
.......................................................
**************** max-log-MAP ****************
mod-Order: 8 | SNR (dB): 14.28888888888889
BER: 0.0
BLER: 0.0
Throughput: 120912000.0
.......................................................
************************************ Training the Model ***********************************
...........................................................................................
Epoch 1/4
1536/1536 [==============================] - 2s 1ms/step - loss: 15.8219 - accuracy: 0.8436
Epoch 2/4
1536/1536 [==============================] - 1s 910us/step - loss: 0.9824 - accuracy: 0.9256
Epoch 3/4
1536/1536 [==============================] - 1s 940us/step - loss: 0.4170 - accuracy: 0.9586
Epoch 4/4
1536/1536 [==============================] - 1s 879us/step - loss: 0.3252 - accuracy: 0.9659
*********************************** Evaluating the Model **********************************
...........................................................................................
1536/1536 [==============================] - 1s 613us/step - loss: 0.2890 - accuracy: 0.9674
Training Accuracy: 96.74
49725/49725 [==============================] - 29s 572us/step
******************* LLRnet ******************
mod-Order: 8 | SNR (dB): 14.28888888888889
BER: 0.0008334987428873892
BLER: 0.2825
Throughput: 86754360.0
_______________________________________________________
+++++++++++ [ snrIndex: 9 | modorder: 8] +++++++++++
===================================================
**************** log-MAP ****************
mod-Order: 8 | SNR (dB): 14.4
BER: 0.0
BLER: 0.0
Throughput: 120912000.0
.......................................................
**************** max-log-MAP ****************
mod-Order: 8 | SNR (dB): 14.4
BER: 0.0
BLER: 0.0
Throughput: 120912000.0
.......................................................
************************************ Training the Model ***********************************
...........................................................................................
Epoch 1/4
1536/1536 [==============================] - 2s 931us/step - loss: 15.7185 - accuracy: 0.8259
Epoch 2/4
1536/1536 [==============================] - 1s 909us/step - loss: 1.0952 - accuracy: 0.9265
Epoch 3/4
1536/1536 [==============================] - 1s 900us/step - loss: 0.4467 - accuracy: 0.9612
Epoch 4/4
1536/1536 [==============================] - 1s 910us/step - loss: 0.3370 - accuracy: 0.9619
*********************************** Evaluating the Model **********************************
...........................................................................................
1536/1536 [==============================] - 1s 623us/step - loss: 0.3024 - accuracy: 0.9624
Training Accuracy: 96.24
49725/49725 [==============================] - 29s 574us/step
******************* LLRnet ******************
mod-Order: 8 | SNR (dB): 14.4
BER: 0.0002639936482731243
BLER: 0.12
Throughput: 106402560.0
_______________________________________________________
Performance Evaluation
Throughput vs SNR (dB) for 16-QAM, 64-QAM and, 256-QAM
[12]:
fig, ax = plt.subplots(1,3, figsize = (10,4))
# For 16-QAM
#********************************************
ax[0].plot(SNRdB[0], Throughput[0,0]/10**6, 'mediumspringgreen', lw = 4, linestyle = "solid", marker = "*", ms = 12, mec = "crimson", mfc = "darkblue", label = "log-MAP")
ax[0].plot(SNRdB[0], Throughput[2,0]/10**6, 'k', lw = 3, linestyle = (0, (3, 1, 1, 1, 1, 1)), marker = "X", ms = 9, mec = "green", mfc = "olive", label = "LLRnet")
ax[0].plot(SNRdB[0], Throughput[1,0]/10**6, 'tomato', lw = 3.5, linestyle = "dotted", marker = "s", ms = 6, mec = "k", mfc = "cyan", label = "max-log-MAP")
ax[0].legend(loc="lower right")
ax[0].set_xlabel("SNR [dB]", fontsize = 9)
ax[0].set_ylabel("Throughput (Mbps)", fontsize = 9)
ax[0].set_title("Throughput vs SNR(dB)", fontsize = 12)
ax[0].set_ylim(0, maxThroughput[2]/10**6)
ax[0].set_xticks(SNRdB[0])
ax[0].grid()
# For 64-QAM
#********************************************
ax[1].plot(SNRdB[1], Throughput[0,1]/10**6, 'mediumspringgreen', lw = 4, linestyle = "solid", marker = "*", ms = 12, mec = "crimson", mfc = "darkblue", label = "log-MAP")
ax[1].plot(SNRdB[1], Throughput[2,1]/10**6, 'k', lw = 3, linestyle = (0, (3, 1, 1, 1, 1, 1)), marker = "X", ms = 9, mec = "green", mfc = "olive", label = "LLRnet")
ax[1].plot(SNRdB[1], Throughput[1,1]/10**6, 'tomato', lw = 3.5, linestyle = "dotted", marker = "s", ms = 6, mec = "k", mfc = "cyan", label = "max-log-MAP")
ax[1].legend(loc="lower right")
ax[1].set_xlabel("SNR [dB]", fontsize = 9)
ax[1].set_title("Throughput vs SNR(dB)", fontsize = 12)
ax[1].set_ylim(0, maxThroughput[2]/10**6)
ax[1].set_xticks(SNRdB[1])
ax[1].grid()
# For 256-QAM
#********************************************
ax[2].plot(SNRdB[2], Throughput[0,2]/10**6, 'mediumspringgreen', lw = 4, linestyle = "solid", marker = "*", ms = 12, mec = "crimson", mfc = "darkblue", label = "log-MAP")
ax[2].plot(SNRdB[2], Throughput[2,2]/10**6, 'k', lw = 3, linestyle = (0, (3, 1, 1, 1, 1, 1)), marker = "X", ms = 9, mec = "green", mfc = "olive", label = "LLRnet")
ax[2].plot(SNRdB[2], Throughput[1,2]/10**6, 'tomato', lw = 3.5, linestyle = "dotted", marker = "s", ms = 6, mec = "k", mfc = "cyan", label = "max-log-MAP")
ax[2].legend(loc="lower right")
ax[2].set_xlabel("SNR [dB]", fontsize = 9)
ax[2].set_ylim(0, maxThroughput[2]/10**6)
ax[2].set_xticks(SNRdB[2])
# Adding Twin Axes to plot using dataset_2
axr = ax[2].twinx()
axr.set_ylabel('Throughput [%]')
# axr.plot(x, dataset_2, color = color)
axr.set_ylim(0, 100)
ax[2].grid()
plt.show()
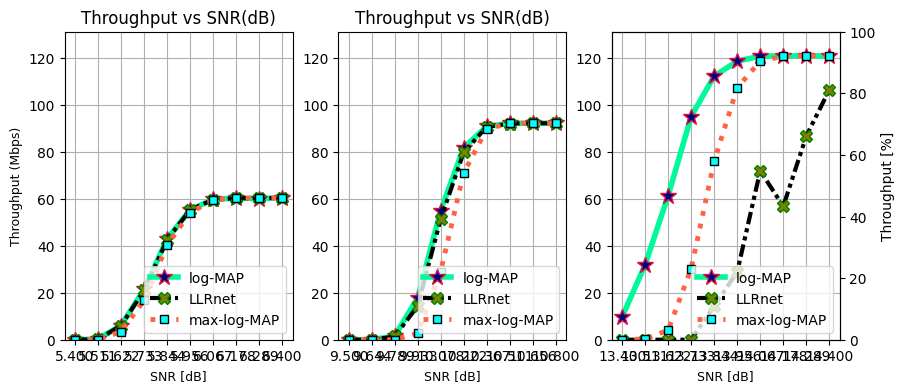
Bit Error rate (BER) vs SNR (dB) for 16-QAM, 64-QAM and, 256-QAM
Comparison with:
max-log-MAP
log-MAP
[13]:
fig, ax = plt.subplots(1,3, figsize = (10,4))
# BER for QAM-16
ax[0].semilogy(SNRdB[0], BER[0,0], 'mediumspringgreen', lw = 4, linestyle = "solid", marker = "*", ms = 12, mec = "crimson", mfc = "darkblue", label = "log-MAP")
ax[0].semilogy(SNRdB[0], BER[2,0], 'k', lw = 3, linestyle = (0, (3, 1, 1, 1, 1, 1)), marker = "X", ms = 9, mec = "green", mfc = "olive", label = "LLRnet")
ax[0].semilogy(SNRdB[0], BER[1,0], 'tomato', lw = 3.5, linestyle = (0, (3, 1, 1, 1, 1, 1)), marker = "s", ms = 6, mec = "k", mfc = "cyan", label = "max-log-MAP")
ax[0].legend(loc="lower left")
ax[0].set_xlabel("SNR [dB]", fontsize = 9)
ax[0].set_ylabel("Bit Error Rate", fontsize = 9)
ax[0].set_title("BER vs SNR(dB)", fontsize = 12)
ax[0].set_xticks(SNRdB[0])
ax[0].grid()
# BER for QAM-64
ax[1].semilogy(SNRdB[1], BER[0,1], 'mediumspringgreen', lw = 4, linestyle = "solid", marker = "*", ms = 12, mec = "crimson", mfc = "darkblue", label = "log-MAP")
ax[1].semilogy(SNRdB[1], BER[2,1], 'k', lw = 3, linestyle = (0, (3, 1, 1, 1, 1, 1)), marker = "X", ms = 9, mec = "green", mfc = "olive", label = "LLRnet")
ax[1].semilogy(SNRdB[1], BER[1,1], 'tomato', lw = 3.5, linestyle = (0, (3, 1, 1, 1, 1, 1)), marker = "s", ms = 6, mec = "k", mfc = "cyan", label = "max-log-MAP")
ax[1].legend(loc="lower left")
ax[1].set_xlabel("SNR [dB]", fontsize = 9)
ax[1].set_ylabel("Bit Error Rate", fontsize = 9)
ax[1].set_title("BER vs SNR(dB)", fontsize = 12)
ax[1].set_xticks(SNRdB[1])
ax[1].grid()
# BER for QAM-256
ax[2].semilogy(SNRdB[2], BER[0,2], 'mediumspringgreen', lw = 4, linestyle = "solid", marker = "*", ms = 12, mec = "crimson", mfc = "darkblue", label = "log-MAP")
ax[2].semilogy(SNRdB[2], BER[2,2], 'k', lw = 3, linestyle = (0, (3, 1, 1, 1, 1, 1)), marker = "X", ms = 9, mec = "green", mfc = "olive", label = "LLRnet")
ax[2].semilogy(SNRdB[2], BER[1,2], 'tomato', lw = 3.5, linestyle = (0, (3, 1, 1, 1, 1, 1)), marker = "s", ms = 6, mec = "k", mfc = "cyan", label = "max-log-MAP")
ax[2].legend(loc="lower left")
ax[2].set_xlabel("SNR [dB]", fontsize = 9)
ax[2].set_ylabel("Bit Error Rate", fontsize = 9)
ax[2].set_title("BER vs SNR(dB)", fontsize = 12)
ax[2].set_xticks(SNRdB[2])
ax[2].grid()
plt.rcParams.update({'font.size': 9})
plt.show()
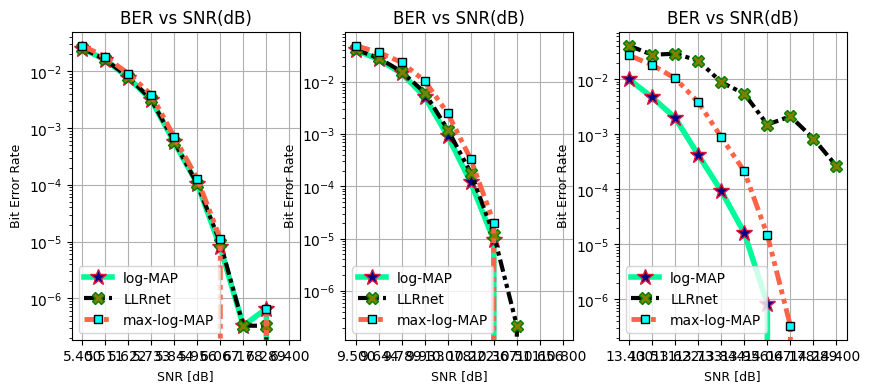
Block Error Rate (BLER) vs SNR (dB) for 16-QAM, 64-QAM and, 256-QAM
Comparison with:
max-log-MAP
log-MAP
[14]:
fig, ax = plt.subplots(1,3, figsize = (10,4))
# BLER for QAM-16
ax[0].semilogy(SNRdB[0], BLER[0,0], 'mediumspringgreen', lw = 4, linestyle = "solid", marker = "*", ms = 12, mec = "crimson", mfc = "darkblue", label = "log-MAP")
ax[0].semilogy(SNRdB[0], BLER[2,0], 'k', lw = 3, linestyle = (0, (3, 1, 1, 1, 1, 1)), marker = "X", ms = 9, mec = "green", mfc = "olive", label = "LLRnet")
ax[0].semilogy(SNRdB[0], BLER[1,0], 'tomato', lw = 3.5, linestyle = (0, (3, 1, 1, 1, 1, 1)), marker = "s", ms = 6, mec = "k", mfc = "cyan", label = "max-log-MAP")
ax[0].legend(loc="lower left")
ax[0].set_xlabel("SNR [dB]", fontsize = 9)
ax[0].set_ylabel("Block Error Rate", fontsize = 9)
ax[0].set_title("BLER vs SNR(dB) for different block-lengths", fontsize = 12)
ax[0].set_xticks(SNRdB[0])
ax[0].grid()
# BER for QAM-64
ax[1].semilogy(SNRdB[1], BLER[0,1], 'mediumspringgreen', lw = 4, linestyle = "solid", marker = "*", ms = 12, mec = "crimson", mfc = "darkblue", label = "log-MAP")
ax[1].semilogy(SNRdB[1], BLER[2,1], 'k', lw = 3, linestyle = (0, (3, 1, 1, 1, 1, 1)), marker = "X", ms = 9, mec = "green", mfc = "olive", label = "LLRnet")
ax[1].semilogy(SNRdB[1], BLER[1,1], 'tomato', lw = 3.5, linestyle = (0, (3, 1, 1, 1, 1, 1)), marker = "s", ms = 6, mec = "k", mfc = "cyan", label = "max-log-MAP")
ax[1].legend(loc="lower left")
ax[1].set_xlabel("SNR [dB]", fontsize = 9)
ax[1].set_ylabel("Block Error Rate", fontsize = 9)
ax[1].set_title("BLER vs SNR(dB) for different block-lengths", fontsize = 12)
ax[1].set_xticks(SNRdB[1])
ax[1].grid()
# BER for QAM-256
ax[2].semilogy(SNRdB[2], BLER[0,2], 'mediumspringgreen', lw = 4, linestyle = "solid", marker = "*", ms = 12, mec = "crimson", mfc = "darkblue", label = "log-MAP")
ax[2].semilogy(SNRdB[2], BLER[2,2], 'k', lw = 3, linestyle = (0, (3, 1, 1, 1, 1, 1)), marker = "X", ms = 9, mec = "green", mfc = "olive", label = "LLRnet")
ax[2].semilogy(SNRdB[2], BLER[1,2], 'tomato', lw = 3.5, linestyle = (0, (3, 1, 1, 1, 1, 1)), marker = "s", ms = 6, mec = "k", mfc = "cyan", label = "max-log-MAP")
ax[2].legend(loc="lower left")
ax[2].set_xlabel("SNR [dB]", fontsize = 9)
ax[2].set_ylabel("Block Error Rate", fontsize = 9)
ax[2].set_title("BLER vs SNR(dB) for different block-lengths", fontsize = 12)
ax[2].set_xticks(SNRdB[2])
ax[2].grid()
plt.rcParams.update({'font.size': 9})
plt.show()
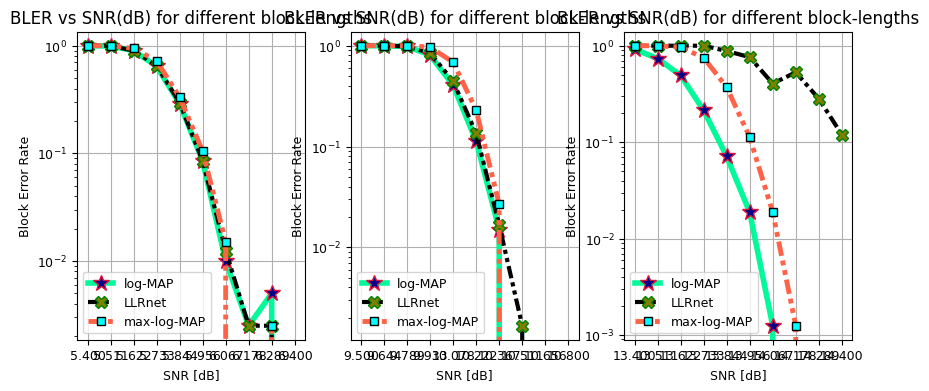
Performance Evaluation: 10000 batches and 64000 training samples for LLRNet
Throughput vs SNR (dB) for 16-QAM, 64-QAM and, 256-QAM.
[15]:
dB = np.load("Database/AggregatedDatabase.npz")
SNRdB = dB["SNRdB"]
BER = dB["BER"]
BLER = dB["BLER"]
Throughput = dB["Throughput"]
[16]:
fig, ax = plt.subplots(1,3, figsize = (10,4))
# For 16-QAM
#********************************************
ax[0].plot(SNRdB[0], Throughput[0,0]/10**6, 'mediumspringgreen', lw = 4, linestyle = "solid", marker = "*", ms = 12, mec = "crimson", mfc = "darkblue", label = "log-MAP")
ax[0].plot(SNRdB[0], Throughput[2,0]/10**6, 'k', lw = 3, linestyle = (0, (3, 1, 1, 1, 1, 1)), marker = "X", ms = 9, mec = "green", mfc = "olive", label = "LLRnet")
ax[0].plot(SNRdB[0], Throughput[1,0]/10**6, 'tomato', lw = 3.5, linestyle = "dotted", marker = "s", ms = 6, mec = "k", mfc = "cyan", label = "max-log-MAP")
ax[0].xaxis.set_major_formatter(FormatStrFormatter('%.1f'))
ax[0].legend(loc="lower right")
ax[0].set_xlabel("SNR [dB]", fontsize = 9)
ax[0].set_ylabel("Throughput (Mbps)", fontsize = 9)
ax[0].set_title("Throughput vs SNR(dB)", fontsize = 12)
ax[0].set_ylim(0, maxThroughput[2]/10**6)
ax[0].set_xticks(SNRdB[0])
plt.rcParams.update({'font.size': 9})
ax[0].grid()
# For 64-QAM
#********************************************
ax[1].plot(SNRdB[1,0:8], Throughput[0,1,0:8]/10**6, 'mediumspringgreen', lw = 4, linestyle = "solid", marker = "*", ms = 12, mec = "crimson", mfc = "darkblue", label = "log-MAP")
ax[1].plot(SNRdB[1,0:8], Throughput[2,1,0:8]/10**6, 'k', lw = 3, linestyle = (0, (3, 1, 1, 1, 1, 1)), marker = "X", ms = 9, mec = "green", mfc = "olive", label = "LLRnet")
ax[1].plot(SNRdB[1,0:8], Throughput[1,1,0:8]/10**6, 'tomato', lw = 3.5, linestyle = "dotted", marker = "s", ms = 6, mec = "k", mfc = "cyan", label = "max-log-MAP")
ax[1].xaxis.set_major_formatter(FormatStrFormatter('%.1f'))
ax[1].legend(loc="lower right")
ax[1].set_xlabel("SNR [dB]", fontsize = 9)
ax[1].set_title("Throughput vs SNR(dB)", fontsize = 12)
ax[1].set_ylim(0, maxThroughput[2]/10**6)
ax[1].set_xticks(SNRdB[1,0:8])
plt.rcParams.update({'font.size': 9})
ax[1].grid()
# For 256-QAM
#********************************************
ax[2].plot(SNRdB[2,0:8], Throughput[0,2,0:8]/10**6, 'mediumspringgreen', lw = 4, linestyle = "solid", marker = "*", ms = 12, mec = "crimson", mfc = "darkblue", label = "log-MAP")
ax[2].plot(SNRdB[2,0:8], Throughput[2,2,0:8]/10**6, 'k', lw = 3, linestyle = (0, (3, 1, 1, 1, 1, 1)), marker = "X", ms = 9, mec = "green", mfc = "olive", label = "LLRnet")
ax[2].plot(SNRdB[2,0:8], Throughput[1,2,0:8]/10**6, 'tomato', lw = 3.5, linestyle = "dotted", marker = "s", ms = 6, mec = "k", mfc = "cyan", label = "max-log-MAP")
ax[2].xaxis.set_major_formatter(FormatStrFormatter('%.1f'))
ax[2].legend(loc="lower right")
ax[2].set_xlabel("SNR [dB]", fontsize = 9)
ax[2].set_ylim(0, maxThroughput[2]/10**6)
ax[2].set_xticks(SNRdB[2,0:8])
# Adding Twin Axes to plot using dataset_2
axr = ax[2].twinx()
axr.set_ylabel('Throughput [%]')
# axr.plot(x, dataset_2, color = color)
axr.set_ylim(0, 100)
plt.rcParams.update({'font.size': 9})
ax[2].grid()
plt.show()
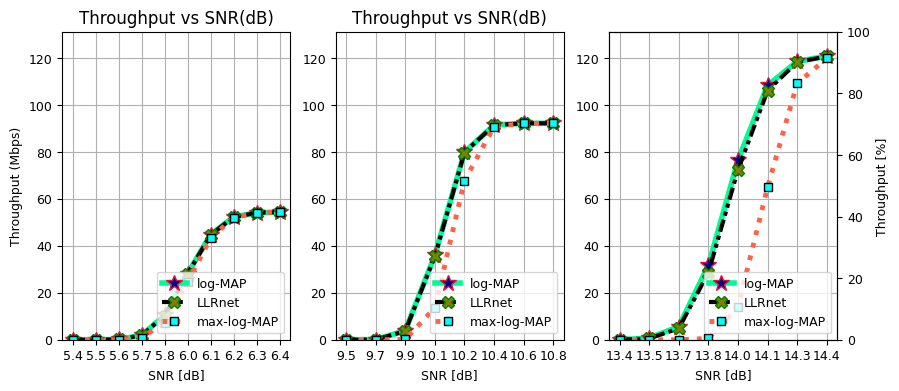
Bit Error rate (BER) vs SNR (dB) for 16-QAM, 64-QAM and, 256-QAM.
Comparison with:
max-log-MAP
log-MAP
[17]:
fig, ax = plt.subplots(1,3, figsize = (10,4))
# BER for QAM-16
ax[0].semilogy(SNRdB[0], BER[0,0], 'mediumspringgreen', lw = 4, linestyle = "solid", marker = "*", ms = 12, mec = "crimson", mfc = "darkblue", label = "log-MAP")
ax[0].semilogy(SNRdB[0], BER[2,0], 'k', lw = 3, linestyle = (0, (3, 1, 1, 1, 1, 1)), marker = "X", ms = 9, mec = "green", mfc = "olive", label = "LLRnet")
ax[0].semilogy(SNRdB[0], BER[1,0], 'tomato', lw = 3.5, linestyle = (0, (3, 1, 1, 1, 1, 1)), marker = "s", ms = 6, mec = "k", mfc = "cyan", label = "max-log-MAP")
ax[0].xaxis.set_major_formatter(FormatStrFormatter('%.1f'))
ax[0].legend(loc="lower left")
ax[0].set_xlabel("SNR [dB]", fontsize = 9)
ax[0].set_ylabel("Bit Error Rate", fontsize = 9)
ax[0].set_title("BER vs SNR(dB)", fontsize = 12)
ax[0].set_xticks(SNRdB[0])
ax[0].grid()
# BER for QAM-64
ax[1].semilogy(SNRdB[1,0:8], BER[0,1,0:8], 'mediumspringgreen', lw = 4, linestyle = "solid", marker = "*", ms = 12, mec = "crimson", mfc = "darkblue", label = "log-MAP")
ax[1].semilogy(SNRdB[1,0:8], BER[2,1,0:8], 'k', lw = 3, linestyle = (0, (3, 1, 1, 1, 1, 1)), marker = "X", ms = 9, mec = "green", mfc = "olive", label = "LLRnet")
ax[1].semilogy(SNRdB[1,0:8], BER[1,1,0:8], 'tomato', lw = 3.5, linestyle = (0, (3, 1, 1, 1, 1, 1)), marker = "s", ms = 6, mec = "k", mfc = "cyan", label = "max-log-MAP")
ax[1].xaxis.set_major_formatter(FormatStrFormatter('%.1f'))
ax[1].legend(loc="lower left")
ax[1].set_xlabel("SNR [dB]", fontsize = 9)
ax[1].set_ylabel("Bit Error Rate", fontsize = 9)
ax[1].set_title("BER vs SNR(dB)", fontsize = 12)
ax[1].set_xticks(SNRdB[1,0:8])
ax[1].grid()
# BER for QAM-256
ax[2].semilogy(SNRdB[2,0:8], BER[0,2,0:8], 'mediumspringgreen', lw = 4, linestyle = "solid", marker = "*", ms = 12, mec = "crimson", mfc = "darkblue", label = "log-MAP")
ax[2].semilogy(SNRdB[2,0:8], BER[2,2,0:8], 'k', lw = 3, linestyle = (0, (3, 1, 1, 1, 1, 1)), marker = "X", ms = 9, mec = "green", mfc = "olive", label = "LLRnet")
ax[2].semilogy(SNRdB[2,0:8], BER[1,2,0:8], 'tomato', lw = 3.5, linestyle = (0, (3, 1, 1, 1, 1, 1)), marker = "s", ms = 6, mec = "k", mfc = "cyan", label = "max-log-MAP")
ax[2].xaxis.set_major_formatter(FormatStrFormatter('%.1f'))
ax[2].legend(loc="lower left")
ax[2].set_xlabel("SNR [dB]", fontsize = 9)
ax[2].set_ylabel("Bit Error Rate", fontsize = 9)
ax[2].set_title("BER vs SNR(dB)", fontsize = 12)
ax[2].set_xticks(SNRdB[2,0:8])
ax[2].grid()
plt.rcParams.update({'font.size': 9})
plt.show()
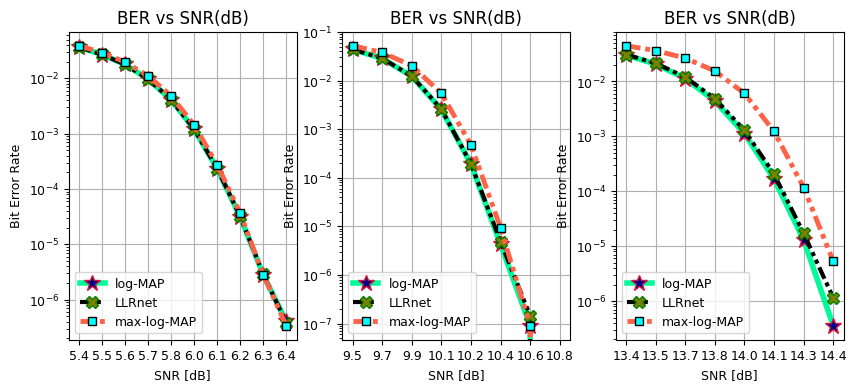
Block Error rate (BER) vs SNR (dB) for 16-QAM, 64-QAM and, 256-QAM.
Comparison with:
max-log-MAP
log-MAP
[18]:
fig, ax = plt.subplots(1,3, figsize = (10,4))
# BLER for QAM-16
ax[0].semilogy(SNRdB[0], BLER[0,0], 'mediumspringgreen', lw = 4, linestyle = "solid", marker = "*", ms = 12, mec = "crimson", mfc = "darkblue", label = "log-MAP")
ax[0].semilogy(SNRdB[0], BLER[2,0], 'k', lw = 3, linestyle = (0, (3, 1, 1, 1, 1, 1)), marker = "X", ms = 9, mec = "green", mfc = "olive", label = "LLRnet")
ax[0].semilogy(SNRdB[0], BLER[1,0], 'tomato', lw = 3.5, linestyle = (0, (3, 1, 1, 1, 1, 1)), marker = "s", ms = 6, mec = "k", mfc = "cyan", label = "max-log-MAP")
ax[0].xaxis.set_major_formatter(FormatStrFormatter('%.1f'))
ax[0].legend(loc="lower left")
ax[0].set_xlabel("SNR [dB]", fontsize = 9)
ax[0].set_ylabel("Block Error Rate", fontsize = 9)
ax[0].set_title("BLER vs SNR(dB) for different block-lengths", fontsize = 12)
ax[0].set_xticks(SNRdB[0])
ax[0].grid()
# BER for QAM-64
ax[1].semilogy(SNRdB[1,0:8], BLER[0,1,0:8], 'mediumspringgreen', lw = 4, linestyle = "solid", marker = "*", ms = 12, mec = "crimson", mfc = "darkblue", label = "log-MAP")
ax[1].semilogy(SNRdB[1,0:8], BLER[2,1,0:8], 'k', lw = 3, linestyle = (0, (3, 1, 1, 1, 1, 1)), marker = "X", ms = 9, mec = "green", mfc = "olive", label = "LLRnet")
ax[1].semilogy(SNRdB[1,0:8], BLER[1,1,0:8], 'tomato', lw = 3.5, linestyle = (0, (3, 1, 1, 1, 1, 1)), marker = "s", ms = 6, mec = "k", mfc = "cyan", label = "max-log-MAP")
ax[1].xaxis.set_major_formatter(FormatStrFormatter('%.1f'))
ax[1].legend(loc="lower left")
ax[1].set_xlabel("SNR [dB]", fontsize = 9)
ax[1].set_ylabel("Block Error Rate", fontsize = 9)
ax[1].set_title("BLER vs SNR(dB) for different block-lengths", fontsize = 12)
ax[1].set_xticks(SNRdB[1,0:8])
ax[1].grid()
# BER for QAM-256
ax[2].semilogy(SNRdB[2,0:8], BLER[0,2,0:8], 'mediumspringgreen', lw = 4, linestyle = "solid", marker = "*", ms = 12, mec = "crimson", mfc = "darkblue", label = "log-MAP")
ax[2].semilogy(SNRdB[2,0:8], BLER[2,2,0:8], 'k', lw = 3, linestyle = (0, (3, 1, 1, 1, 1, 1)), marker = "X", ms = 9, mec = "green", mfc = "olive", label = "LLRnet")
ax[2].semilogy(SNRdB[2,0:8], BLER[1,2,0:8], 'tomato', lw = 3.5, linestyle = (0, (3, 1, 1, 1, 1, 1)), marker = "s", ms = 6, mec = "k", mfc = "cyan", label = "max-log-MAP")
ax[2].xaxis.set_major_formatter(FormatStrFormatter('%.1f'))
ax[2].legend(loc="lower left")
ax[2].set_xlabel("SNR [dB]", fontsize = 9)
ax[2].set_ylabel("Block Error Rate", fontsize = 9)
ax[2].set_title("BLER vs SNR(dB) for different block-lengths", fontsize = 12)
ax[2].set_xticks(SNRdB[2,0:8])
ax[2].grid()
plt.rcParams.update({'font.size': 9})
plt.show()
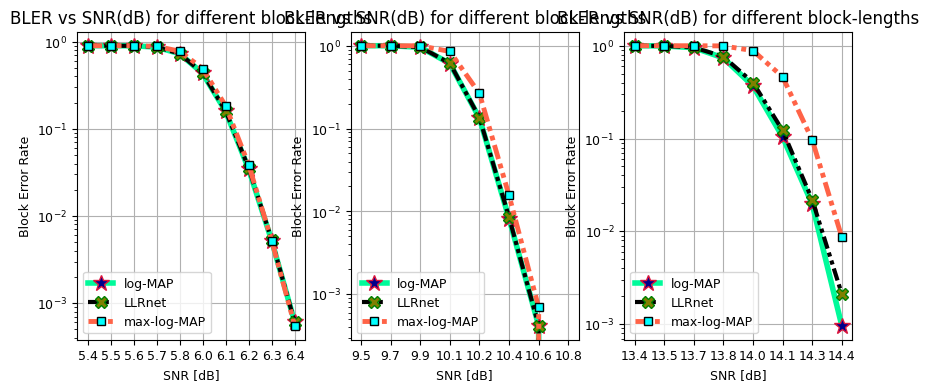
Complexity Analysis
Computational Complexity vs Throughput.
Computational Complexity vs BER/BLER.
Comparison with max-log-MAP and log-MAP.
Note: The throughput data used in following calculations is taken from the above simulations and the computational complexity number are provided by author in the paper. The complexity number for this paer may be slighlty different due to over configured model used for the simulation.
[19]:
complexityLogMAP = np.array([832, 3840, 17408])
complexityMaxLogMAP = np.array([208, 680, 5000])
complexityLLRnet = np.array([240, 608, 1472])
normalizedComplexityMaxLogMAP = complexityMaxLogMAP/complexityLogMAP*100
normalizedComplexityLLRnet = complexityLLRnet/complexityLogMAP*100
throughPutLogMAP = np.array([28.2, 60.05, 90.4]) # @ SNR (dB) = 5
throughPutMaxLogMAP = np.array([24.75, 42.12, 49.2]) # @ SNR (dB) = 10
throughPutLLRnet = np.array([28.03, 59.94, 90.1]) # @ SNR (dB) = 14.25
normalizedThroughPutMaxLogMAP = (1-throughPutMaxLogMAP/throughPutLogMAP)*100
normalizedThroughPutLLRnet = (1-throughPutLLRnet/throughPutLogMAP)*100
SNRdBValues = [5, 10, 14.25]
modOrder = [16,64,256]
fig, ax = plt.subplots()
ax.scatter(normalizedComplexityLLRnet, normalizedThroughPutLLRnet, marker = 'o', edgecolors="blue", facecolors="blue", s = 200, label = "LLRnet")
ax.scatter(normalizedComplexityMaxLogMAP, normalizedComplexityMaxLogMAP, marker = '^', edgecolors="red", facecolors="red", s = 200, label = "max-log-MAP")
for i in range(3):
plt.plot([normalizedComplexityLLRnet[i], normalizedComplexityMaxLogMAP[i]], [normalizedThroughPutLLRnet[i], normalizedComplexityMaxLogMAP[i]], ':')
plt.text(normalizedComplexityMaxLogMAP[i], normalizedComplexityMaxLogMAP[i],"QAM-"+str(modOrder[i])+", "+str(SNRdBValues[i])+"dB")
ax.set_xlabel("Relative Complexity [%]")
ax.set_ylabel("Relative Throughput loss [%]")
ax.set_xlim(0,100)
ax.set_ylim(0,normalizedThroughPutMaxLogMAP.max()+10)
ax.grid()
ax.legend()
plt.show()
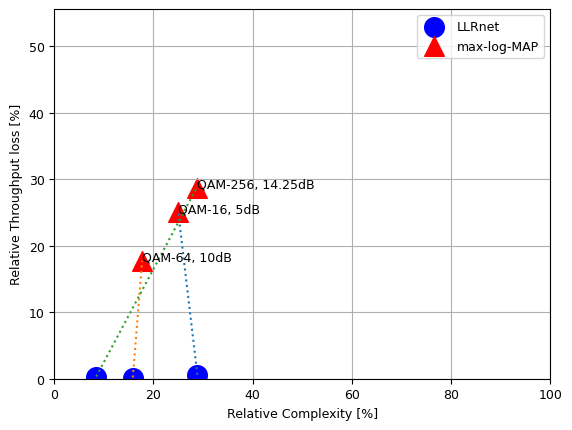
Conclusion
Now that we have understood LLRnet, we are in a position to discuss the positives and the limitations of this model.
Positives of the LLRnet:
The positive of using LLRnet for decoding/demapping the equalized symbols are:
Low complexity and requires few samples for training.
Not impractical to train even online in real-time for demapping.
Limitations of the LLRnet:
On the other hand there are a few limitations of the techniques:
Robustness:
Performance is sensitive to estimate of SNR available.
Generalization:
Different models are required for different modulation orders.
Not generalized for all the SNRs.
Power consumption vs Cost:
Deployment of multiple models (for different modulation order and SNR) is computationally efficient but occupy large silicon (Si) space on FPGA or SoC.
Larger the silicon required, higher the cost and bulkier the device.
References:
Shental and J. Hoydis, “”Machine LLRning”: Learning to Softly Demodulate,” 2019 IEEE Globecom Workshops (GC Wkshps), Waikoloa, HI, USA, 2019, pp. 1-7, doi: 10.1109/GCWkshps45667.2019.9024433.
Python code for LLRNet.
[ ]: